📑 목차
갑자기 로그인 실패가 폭증할 때 가장 먼저 확인하는 장면
로그인 실패가 짧은 시간에 급증하면 “서버가 불안정한가”부터 떠올리기 쉽다.
그러나 인증 구간은 정상인데, 실패 요청만 늘어나는 경우가 많다. 이때는 공격 패턴을 먼저 가정하고 로그 흔적을 기준으로 분류하는 편이 빠르다.
현장에서 자주 만나는 초기 상황은 다음과 같다.
- 5~10분 사이 로그인 실패(401/403)가 평소 대비 수십 배로 증가한다
- 특정 계정의 실패가 몰리거나, 반대로 여러 계정이 조금씩 실패한다
- 성공(200)도 일부 섞여 보이며, 이후 비정상 행동(비밀번호 변경, 결제 시도)이 뒤따른다
흔한 오해는 “실패가 많이 보이면 전부 브루트포스일 것”이라는 판단이다.
실패량만으로는 구분이 되지 않는다. 같은 실패 급증이라도 계정 분포, IP 분포, 성공률의 모양이 다르게 나온다.
아래는 로그에서 자주 보이는 형태를 단순화한 예시다.
2026-01-05T10:03:12Z POST /login ip=203.0.113.10 user=kim*** ua="Mozilla/5.0" status=401 reason=invalid_password 2026-01-05T10:03:13Z POST /login ip=203.0.113.10 user=kim*** ua="Mozilla/5.0" status=401 reason=invalid_password 2026-01-05T10:03:14Z POST /login ip=203.0.113.10 user=kim*** ua="Mozilla/5.0" status=401 reason=invalid_password같은 IP와 같은 계정이 반복되면 브루트포스 쪽 모양이 강해진다.

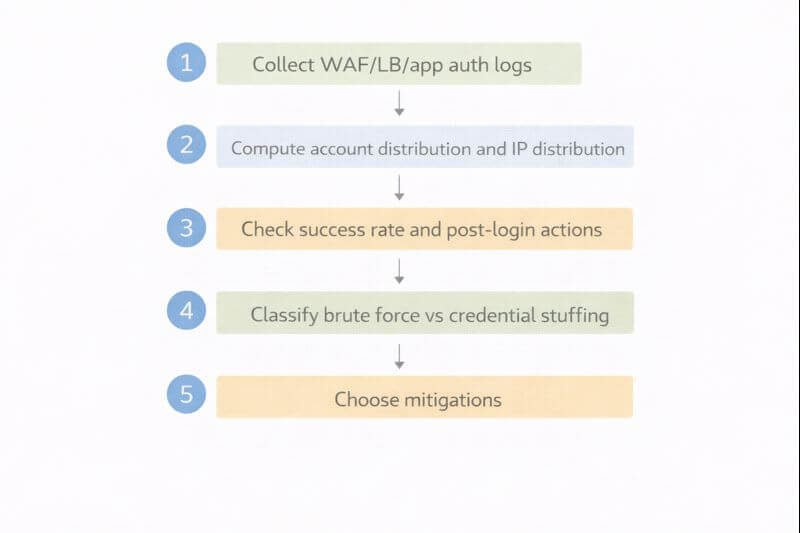
로그에서 바로 잡히는 체크 포인트 3가지로 방향을 정한다
패턴 구분은 복잡한 탐지 모델보다 “분포의 모양”을 먼저 보는 것이 현실적이다.
아래 세 가지를 잡으면 브루트포스와 크리덴셜 스터핑이 빠르게 갈린다.
- 체크 포인트 1: 계정 분포가 좁은가 넓은가(한 계정 집중 vs 다수 계정 분산)
- 체크 포인트 2: IP 분포가 좁은가 넓은가(소수 IP 반복 vs 다수 IP 분산)
- 체크 포인트 3: 성공률과 성공 후 행동이 어떤가(거의 0% vs 낮지만 실제 성공이 섞임)
이 세 가지는 로그 저장 위치가 달라도 공통으로 계산할 수 있다.
CDN/WAF 로그, 로드밸런서 액세스 로그, 애플리케이션 인증 로그 중 무엇을 먼저 보더라도 분포는 드러난다.
두 패턴의 핵심 차이를 정의로 묶어 오판을 줄인다
브루트포스(Brute Force)
정의: 하나 또는 소수 계정을 대상으로 비밀번호를 여러 번 대입하며 로그인 성공을 노리는 시도다.
핵심 특징: 동일 계정에 실패가 연속으로 쌓이고, 같은 IP 또는 좁은 IP 대역에서 반복되는 경우가 많다.
주의점: 계정 잠금 정책이 강하면 성공률은 낮아 보일 수 있으나, 서비스 가용성(로그인 지연)과 정상 사용자 차단이 함께 커질 수 있다.
크리덴셜 스터핑(Credential Stuffing)
정의: 이미 유출된 아이디/비밀번호 조합을 대량으로 가져와 여러 계정에 “한두 번씩” 대입해 성공을 노리는 시도다.
핵심 특징: 계정이 넓게 분산되고, IP도 분산되는 경향이 강하다. 실패가 많아도 일정 비율의 성공이 섞이기도 한다.
주의점: 성공 자체가 로그인 단계에서 끝나지 않고, 성공 후 빠르게 계정 변경·결제·포인트 사용 같은 행동이 이어질 수 있다.
둘을 구분하는 목적은 이름 맞히기가 아니다.
차단 전략이 달라지기 때문에, 로그 흔적으로 “어느 쪽에 가까운지”를 먼저 고정해야 한다.
| 판별 축 | 브루트포스 쪽 흔적 | 크리덴셜 스터핑 쪽 흔적 |
|---|---|---|
| 계정 분포 | 특정 계정 1~수 개에 실패가 집중된다 | 여러 계정이 조금씩 실패하며 목록이 넓다 |
| IP 분포 | 소수 IP/대역에서 반복되기 쉽다 | 다수 IP로 분산되며 교체가 잦을 수 있다 |
| 시도 간격 | 짧은 간격의 연속 시도가 보인다 | 계정당 시도 횟수는 적고 전체 양만 많다 |
| 성공률 | 대체로 매우 낮고, 성공이 거의 없을 수 있다 | 낮지만 성공이 섞이는 경우가 상대적으로 많다 |
| 성공 후 행동 | 성공이 드물어 후속 행동 데이터가 빈약할 수 있다 | 성공 직후 계정 설정 변경·결제 시도가 이어질 수 있다 |
판별을 빠르게 만드는 확인 절차: 어디 로그를 어떤 순서로 볼지
로그가 여러 군데 흩어져 있어도 순서를 고정하면 판단 속도가 빨라진다.
아래 절차는 “어디에서 무엇을 확인할지”가 포함된 형태로 정리했다.
- 경로: CDN/WAF 대시보드 → Security Events(또는 Firewall Events) → 로그인 경로(/login, /auth) 필터
- 체크 포인트: 차단/허용 비율, 상위 IP, 상위 국가/ASN, 사용자 에이전트(UA) 다양성을 확인한다.
- 경로: 로드밸런서/웹서버 액세스 로그 → /login 요청만 추출 → 상태코드(200/401/403/429) 집계
- 체크 포인트: 429(레이트 리밋)가 증가하는지, 401이 폭증하는지, 200이 섞이는지 확인한다.
- 경로: 애플리케이션 인증 로그 → 실패 사유(reason)와 계정 식별자(user/email) 기준으로 그룹화
- 체크 포인트: 특정 계정에 실패가 집중되는지, 계정 목록이 넓게 퍼지는지 확인한다.
- 경로: 성공 로그인 로그 → 성공 직후 행동 로그(비밀번호 변경, 결제, 이메일 변경 등) 연계 조회
- 체크 포인트: 성공 직후 민감 기능 호출이 급증하면 크리덴셜 스터핑을 우선 의심한다.
- 경로: 알림/모니터링 규칙 → 동일 기간의 정상 트래픽(홍보/공지/이벤트) 여부 확인
- 체크 포인트: 정상 캠페인 유입으로 인한 실패 증가인지, 인증 경로만 비정상적으로 증가했는지 분리한다.
집계가 어려우면 아래처럼 “계정 기준”과 “IP 기준”으로 한 번씩만 뽑아도 형태가 보인다.
# 계정 기준: 상위 실패 계정 확인(개념적 예시) count_failed_by_user = group(login_fail_logs, key=user).count().sort_desc().top(20)
IP 기준: 상위 실패 IP 확인(개념적 예시)
count_failed_by_ip = group(login_fail_logs, key=ip).count().sort_desc().top(20)상위 실패 계정이 몇 개에 몰리면 브루트포스 쪽으로, 상위 실패 IP와 실패 계정이 함께 넓게 퍼지면 크리덴셜 스터핑 쪽으로 기운다.
실전 예시 1개: “성공이 조금 섞이는” 로그인 실패 폭증
문제: 30분 동안 로그인 실패가 18,000건으로 급증했고, 성공(200)도 40건 정도 섞여 있었다.
왜 발생: 실패는 여러 계정에 분산되어 있었고, IP도 짧은 주기로 바뀌었다. 성공한 계정 일부에서 이메일 변경 시도가 이어졌다.
어떤 선택이 적합: 계정 보호를 우선으로 두고, 성공 후 민감 기능에 추가 검증을 붙이며, 동일한 장치/세션 특성이 없는 로그인을 단계적으로 제한하는 접근이 맞다.
잘못 쓰면 어떤 문제: IP 기준으로만 과하게 차단하면 정상 사용자가 함께 막히고, 공격자는 IP를 바꿔 계속 들어온다.
확인/해결: 인증 로그에서 실패 계정 목록의 폭을 확인하고, 성공 로그의 후속 행동을 연계 조회한 뒤, 레이트 리밋을 계정 단위로 보강하고 성공 후 민감 기능에 추가 인증을 적용한다.
재발 방지와 운영 체크리스트: 차단을 “정확하게” 만드는 방법
패턴이 브루트포스 쪽이면 “한 계정 집중”을 꺾는 쪽이 효율적이다.
패턴이 크리덴셜 스터핑 쪽이면 “다수 계정 분산 + 일부 성공”을 전제로 계정 보호를 강화해야 한다.
- 브루트포스 대응: 계정 단위 실패 횟수 기반 지연, 계정 잠금은 짧게, 정상 사용자 복구 경로(잠금 해제/비밀번호 재설정)를 준비한다
- 크리덴셜 스터핑 대응: 성공 후 민감 기능에 추가 인증, 의심 로그인에 단계적 제한, 동일 장치/세션 신호 기반의 위험 점수화를 적용한다
- 공통 대응: 429 응답 정책, CAPTCHA/추가 검증의 조건을 “실패 분포”에 맞춰 조정하고, 과잉 차단으로 인한 고객 불편을 모니터링한다
배포/운영 체크리스트는 아래 항목을 기준으로 점검하는 편이 안정적이다.
- 로그 필드: ip, user, ua, status, reason, 요청 경로, 응답시간, 상관관계 ID를 남기고 누락 여부를 확인한다
- 알림 기준: 실패 총량뿐 아니라 계정 집중도(상위 계정 실패 비율)와 성공 후 민감 기능 호출 급증을 분리해 감시한다
- 차단 기준: IP 단독 차단에 의존하지 않고, 계정 단위 제한과 조합해 우회 비용을 올린다
- 정상 사용자 보호: 잠금/차단 시 안내 문구와 복구 절차가 막히지 않는지 운영 화면에서 확인한다
- 사후 조치: 성공이 섞였던 경우 비밀번호 초기화 권고, 세션 무효화, 민감 기능 로그 감사 범위를 정한다
결론
실패량만으로는 브루트포스와 크리덴셜 스터핑을 구분하기 어렵다.
계정 분포, IP 분포, 성공률과 성공 후 행동이라는 “로그 흔적의 모양”을 먼저 고정하면 오판이 줄어든다.
분류가 끝나면 차단 전략도 달라지며, 특히 크리덴셜 스터핑은 성공 후 민감 기능 보호가 함께 가야 한다.
연계 주제 제안: 위험 기반 인증(로그인 위험 점수화) 설계, 정상 사용자 방해를 줄이는 레이트 리밋과 CAPTCHA 조건 설계가 다음 주제로 이어지기 좋다.
FAQ
두 패턴이 동시에 섞여 보이면 어떻게 판단하나?
한 계정에 집중된 실패 덩어리와 다수 계정에 분산된 실패 덩어리가 동시에 보일 수 있다.
이때는 시간 구간을 잘라 분포를 다시 계산하고, 성공 후 행동이 있는지로 우선순위를 정하는 편이 빠르다.
성공 로그가 거의 없는데도 크리덴셜 스터핑일 수 있나?
가능하다. 유출된 조합이 오래되었거나 서비스가 이미 보강되어 성공률이 낮을 수 있다.
계정 분포가 넓고 계정당 시도 횟수가 얕게 유지된다면 스터핑 쪽 흔적이 남는다.
차단 임계값을 숫자로 고정해도 되나?
고정 임계값은 정상 이벤트 트래픽에 의해 오탐이 늘 수 있다.
실패 총량보다 계정 집중도, 429 비율, 성공 후 민감 기능 호출 같은 조합 지표로 조건을 구성하는 편이 운영에서 덜 흔들린다.
'전산학' 카테고리의 다른 글
| 입력값 검증의 ‘경계’ 문제: 프론트·백엔드 역할 분담으로 XSS·SQL 인젝션을 줄이는 방법 (0) | 2025.12.30 |
|---|---|
| 세션 하이재킹 실전 흐름: 쿠키 탈취부터 방어(HTTPS·HttpOnly·SameSite)까지 한 번에 정리 (0) | 2025.12.30 |
| 헬스 체크를 잘못 만들면 장애가 커진다: liveness/readiness/startup 개념과 안전한 설계 예시 (0) | 2025.12.30 |
| 로그가 ‘쓸모 없어지는’ 이유: 로그 레벨보다 중요한 필드(요청 ID·에러 코드·지연 시간) 설계 (0) | 2025.12.29 |
| 마이크로서비스 전환이 실패하는 5가지 신호: 분리 기준·공유 DB·배포 복잡도 체크리스트 (0) | 2025.12.29 |



