📑 목차
장애를 키우는 헬스 체크 오해: “체크가 많을수록 안전하다”
운영 중 장애가 나면 “헬스 체크를 더 촘촘히 넣자”는 결론으로 흐르기 쉽다.
그러나 체크가 늘었다고 장애가 줄지는 않는다. 오히려 잘못된 체크가 정상 인스턴스를 계속 죽이거나, 아직 준비되지 않은 인스턴스에 트래픽을 밀어 넣어 장애를 키우기도 한다.
현장에서 자주 보이는 문제 장면은 다음과 같다.
- 배포 직후 트래픽이 몰리면서 일부 파드가 계속 재시작되고, 전체 응답이 불안정해진다
- 컨테이너는 살아 있는데 특정 스레드가 멈춘 상태라서, 장애가 길게 이어진다
- “헬스 체크는 통과”인데 사용자는 계속 실패를 겪고, 로그에는 타임아웃만 늘어난다
많이 하는 착각은 “liveness만 통과하면 서비스도 정상일 것”이라는 생각이다.
liveness는 ‘살아 있음’에 관한 신호이고, ‘트래픽을 받아도 되는 상태’와는 다를 수 있다.
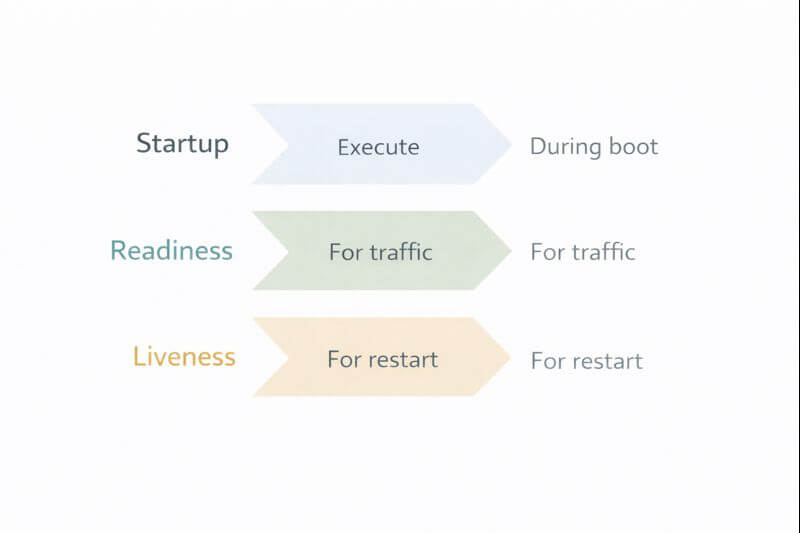
핵심 개념 2개: liveness와 readiness를 역할로 나눠야 한다
liveness probe
정의: 프로세스가 비정상 상태에 빠져 더 이상 정상 복구가 어렵다고 판단될 때, 재시작으로 회복시키기 위한 신호다.
핵심 특징: 실패하면 오케스트레이터가 해당 인스턴스를 재시작하는 방향으로 움직인다.
핵심 특징: 정상이어야 할 것은 “프로세스가 계속 전진할 수 있는가”이며, “트래픽을 받을 준비”와는 구분된다.
주의점: 시작 직후에는 일시적으로 실패하기 쉬운 체크를 넣으면, 정상 기동 중인 인스턴스를 계속 죽여 장애를 만들 수 있다.
readiness probe
정의: 현재 인스턴스가 요청을 받아도 되는 상태인지 판단해, 트래픽 라우팅 대상에 포함할지 결정하기 위한 신호다.
핵심 특징: 실패해도 보통 재시작이 아니라 “트래픽 제외”가 일어난다.
핵심 특징: 캐시 워밍업, DB 연결 안정화, 의존 서비스 준비 여부 같은 “준비 완료”를 담기 좋다.
주의점: readiness가 지나치게 느슨하면 준비되지 않은 인스턴스가 트래픽을 받아 실패율이 오른다.
startup probe는 이 두 신호가 흔히 충돌하는 구간, 즉 “기동 중”을 다루기 위한 장치다.
기동이 길거나 초기 의존성 연결이 불안정한 서비스라면 startup을 따로 잡지 않으면 liveness가 기동을 방해할 수 있다.
비교표와 YES/NO 체크리스트: 지금 설정이 ‘안전한지’ 빠르게 가른다
같은 HTTP 체크라도 의미가 달라진다. 실패했을 때 무엇이 일어나는지부터 분리해야 한다.
| 구분 | startup | readiness | liveness |
|---|---|---|---|
| 목적 | 기동 중인지 판단해 초기 실패를 허용한다 | 트래픽을 받아도 되는지 결정한다 | 멈춤/교착 등 회복 불가 상태를 재시작으로 풀려 한다 |
| 실패 시 영향 | 기동 완료 전에는 다른 프로브를 보호하는 역할이 된다 | 라우팅 대상에서 제외되어 요청이 덜 들어온다 | 재시작이 발생할 수 있다 |
| 추천 체크 | 프로세스 기동 완료 여부, 기본 핸들러 응답 | 핵심 의존성 준비, 캐시/연결 상태, 내부 큐 적체 임계 | 프로세스 전진 여부, 치명적 교착 신호, 최소 기능 응답 |
| 흔한 실수 | 기동 시간이 긴데 startup 없이 liveness를 바로 켠다 | 준비가 덜 됐는데 OK를 반환해 트래픽을 받는다 | 외부 API/DB 실패를 liveness 실패로 처리해 재시작 폭주를 만든다 |
아래 체크리스트는 운영 중 “이 설정이 장애를 키울 가능성이 있는지”를 빠르게 나눈다.
- YES: readiness 실패는 재시작이 아니라 트래픽 제외로만 이어진다
- YES: liveness는 외부 의존성 장애(일시적 DB 지연 등)와 분리되어 있다
- YES: 기동 시간이 길 때 startup으로 기동 구간을 따로 보호한다
- NO: 배포 직후 재시작이 급증하고 CrashLoopBackOff가 반복된다
- NO: DB 연결 지연이나 외부 API 오류만 있어도 liveness가 실패한다
- NO: readiness가 항상 OK라서, 준비되지 않은 인스턴스도 트래픽을 그대로 받는다
안전한 설계 예시: 확인 절차와 실전 상황 1개로 끝까지 점검한다
문제: 배포 직후 1~2분 동안 간헐적으로 5xx가 증가하고, 파드가 반복 재시작된다.
왜 발생: 서비스는 기동 중이며 의존성 연결과 캐시 초기화가 끝나지 않았는데, liveness가 이를 실패로 판단해 컨테이너를 계속 죽였다.
어떤 선택이 적합: 기동 구간은 startup으로 보호하고, 트래픽 투입은 readiness로 늦추며, liveness는 “교착/무응답”처럼 재시작이 진짜 도움이 되는 조건으로만 좁힌다.
잘못 쓰면 어떤 문제: 정상 기동이 반복적으로 중단되어 전체 배포가 길어지고, 트래픽이 남은 인스턴스에 몰려 연쇄 장애가 커질 수 있다.
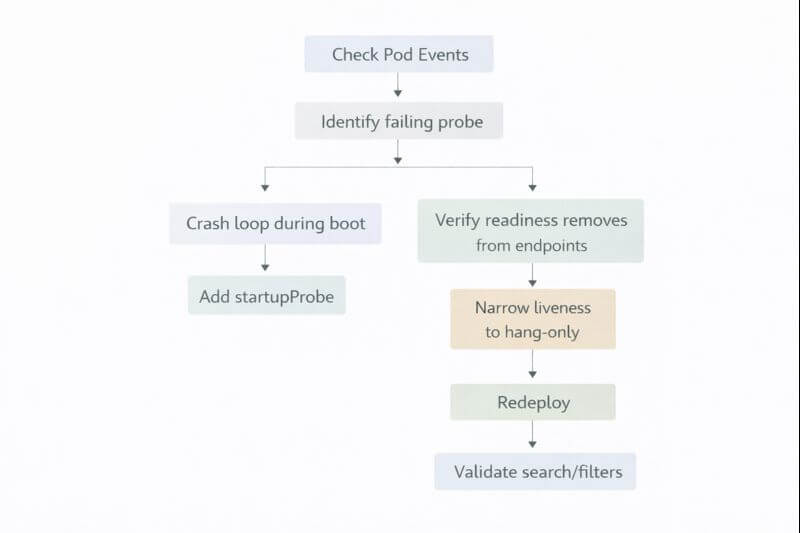
아래는 운영자가 바로 따라 할 수 있는 단계형 확인 절차다.
- 경로: Kubernetes Dashboard → Workloads → Pods → 해당 Pod 선택 → Events체크 포인트: 재시작 횟수가 배포 직후에만 튀는지, 계속 증가하는지 구분한다.
- 체크 포인트: “Unhealthy” 이벤트가 어떤 프로브에서 발생하는지(liveness/readiness/startup)를 확인한다.
- 경로: 터미널 → kubectl describe pod <pod-name> 실행 결과 확인
- 체크 포인트: 마지막 실패 원인, 실패 횟수, 실패 메시지(타임아웃/연결 실패 등)를 확인한다.
- 경로: 터미널 → kubectl logs <pod-name> --previous 확인체크 포인트: 실제 오류가 애플리케이션 내부 교착인지, 외부 의존성 대기인지 구분한다.
- 체크 포인트: 재시작 직전 로그에 “기동 단계 진행 중” 신호가 있었는지 확인한다.
- 경로: Deployment/Pod 매니페스트 → probes 설정 섹션 확인체크 포인트: readiness는 “트래픽을 받으면 실패할 조건”을 포함하는지 점검한다.
- 체크 포인트: startupProbe 유무를 확인하고, 기동 시간보다 failureThreshold×periodSeconds가 짧지 않은지 본다.
- 경로: 서비스 라우팅 확인 → kubectl get endpoints <service-name> 또는 인그레스/서비스 대시보드체크 포인트: 준비되지 않은 파드로 트래픽이 들어가는 흔적이 있는지 확인한다.
- 체크 포인트: readiness 실패 시 해당 파드가 endpoints에서 빠지는지 확인한다.
설계 시 주의사항: “재시작”을 처방처럼 쓰지 않는다
liveness를 외부 의존성 상태로 묶으면, 의존성이 흔들리는 순간마다 재시작이 폭주한다.
readiness는 일시적 불안정 구간을 트래픽에서 격리하는 데 쓰는 편이 자연스럽다.
startup은 기동이 길거나 초기화가 많은 서비스에서, “기동 중 정상 실패”를 장애로 오판하지 않도록 분리하는 장치로 쓰기 좋다.
결론
liveness는 재시작이 필요한 상태를, readiness는 트래픽을 받을 준비 상태를 다룬다.
startup을 분리하면 기동 구간에서 liveness 오판으로 인한 재시작 폭주를 줄일 수 있다.
이벤트·로그·엔드포인트 변화를 단계적으로 확인하면, 프로브가 장애를 줄이는지 키우는지 빠르게 판단할 수 있다.
연계 주제 제안: 배포 전략(롤링 업데이트에서 surge/unavailable 조정)과 readiness 연동 방법, 장애 전파를 줄이는 타임아웃·재시도 설계가 다음 단계로 이어지기 좋다.
FAQ
readiness가 실패하면 사용자는 어떤 변화를 겪나?
보통 해당 인스턴스는 라우팅 대상에서 빠져 요청이 덜 들어온다.
인스턴스 수가 충분하면 사용자는 큰 변화를 못 느끼고, 부족하면 대기나 지연이 늘어날 수 있다.
liveness 체크에 DB 연결 여부를 넣으면 안 되나?
DB 지연은 일시적일 수 있어, 이를 liveness 실패로 만들면 재시작이 연쇄로 발생할 수 있다.
DB 의존성은 readiness에서 트래픽 차단으로 다루고, liveness는 교착이나 무응답처럼 재시작이 실제로 도움이 되는 조건으로 좁히는 편이 안전하다.
startupProbe를 쓰면 서비스 준비가 늦어지는가?
startupProbe는 기동 중에 다른 프로브로 인한 오판을 막는 역할이어서, 준비 자체를 늦추는 장치는 아니다.
기동 시간이 긴 서비스에서는 오히려 불필요한 재시작을 줄여 전체 준비 시간이 안정적으로 짧아질 수 있다.
'전산학' 카테고리의 다른 글
| 세션 하이재킹 실전 흐름: 쿠키 탈취부터 방어(HTTPS·HttpOnly·SameSite)까지 한 번에 정리 (0) | 2025.12.30 |
|---|---|
| 로그가 ‘쓸모 없어지는’ 이유: 로그 레벨보다 중요한 필드(요청 ID·에러 코드·지연 시간) 설계 (0) | 2025.12.29 |
| 마이크로서비스 전환이 실패하는 5가지 신호: 분리 기준·공유 DB·배포 복잡도 체크리스트 (0) | 2025.12.29 |
| 캐시가 오히려 느리게 만드는 순간: 캐시 무효화 실패와 ‘오래된 데이터’ 버그를 잡는 흐름 (0) | 2025.12.29 |
| 세션 스토리지와 로컬 스토리지: 전산학 브라우저 안에 데이터를 보관하는 여러 방식 (0) | 2025.12.28 |



