📑 목차
락 경합이 체감되는 첫 순간
락(Lock)과 락 경합은 "데이터는 안전해졌는데 서비스가 갑자기 느려지는" 전형적인 계기를 만든다.
평소엔 잘 버티던 API가 특정 시간대에만 지연되고, CPU 사용률은 높지 않은데 응답 시간이 길게 늘어나는 패턴이 자주 보인다.
특히 쓰기 트래픽이 몰리거나, 같은 자원을 여러 요청이 동시에 만지는 구간에서 "줄 서기"가 생기면 체감 성능이 급격히 떨어진다.
이 현상은 코드를 크게 바꾸지 않았는데도 트래픽이 늘어나거나 배포 이후 동시성이 달라졌을 때 더 자주 나타난다.
락(Lock)이 지키는 것과 잃는 것
락(Lock)은 여러 스레드나 프로세스가 같은 공유 자원을 동시에 건드릴 때, "한 번에 한 명만 들어가게" 만들어 데이터 손상을 막는다.
이때 락이 보호하는 구간을 임계 구역이라 부르며, 임계 구역이 길어질수록 다른 작업은 그만큼 오래 기다린다.
락을 걸면 안전성은 올라가지만, 동시에 처리되는 양은 임계 구역의 길이와 락 획득 경쟁 정도에 의해 제한된다.
안전과 속도는 항상 반대가 아니라, "어디를 잠그느냐"와 "얼마나 오래 잠그느냐"에 따라 결과가 갈린다.
락 경합이 느려지는 진짜 이유
락 경합이 느려지는 이유는 단순히 "락을 썼기 때문"이 아니라, 경쟁이 늘어나면서 대기가 기하급수로 늘어나는 구조 때문이다.
요청이 2배가 되면 대기는 2배가 아니라 더 크게 튈 수 있는데, 이는 한 번에 한 작업만 통과하는 병목 지점에 대기열이 쌓이기 때문이다.
또한 락을 잡은 스레드가 I/O(디스크/네트워크)나 긴 계산을 함께 수행하면, 임계 구역이 불필요하게 길어져 경합이 폭발한다.
마지막으로 락 범위가 넓으면 "잠가야 할 필요가 없는 부분"까지 함께 잠기면서, 실제 병목이 아닌 곳까지 연쇄 지연이 퍼진다.
락(Lock) 종류에 따라 경합이 보이는 방식
락 경합은 어떤 락을 쓰느냐에 따라 증상이 다르게 보인다.
읽기 위주의 시스템에서 쓰기 락이 드물게 잡히면 평소엔 빠르지만, 특정 이벤트에서만 전체가 멈춘 듯 보일 수 있다.
| 락 형태 | 뮤텍스/모니터 |
|---|---|
| 설명 | 한 번에 하나만 통과시키는 락 |
| 경합이 늘면 | 대기열이 길어지고 p95/p99 지연이 크게 튀는 현상 |
| 대표적 원인 | 임계 구역이 길다, 같은 키/같은 객체에 요청이 몬다 |
| 락 형태 | 읽기-쓰기 락 |
| 설명 | 읽기는 여러 개, 쓰기는 단독인 락 |
| 경합이 늘면 | 쓰기 작업이 들어오는 순간 읽기 흐름까지 기다림 발생 |
| 대표적 원인 | 쓰기 빈도 상승, 읽기 작업이 락을 오래 붙잡음 |
| 락 형태 | DB 트랜잭션 락 |
| 설명 | 행/테이블 락 등 데이터 단위로 잡는 락 |
| 경합이 늘면 | 특정 쿼리가 오래 걸리면 관련 요청들이 줄줄이 멈춤 |
| 대표적 원인 | 인덱스 부재, 넓은 범위 갱신, 트랜잭션이 오래 열림 |
결국 락 경합을 줄이는 핵심은 "임계 구역을 짧게"와 "경쟁 대상을 쪼개기"로 정리된다.
YES/NO 체크리스트로 락 경합을 빠르게 의심하기
락 경합은 관측 포인트를 잡으면 초기에 빠르게 가닥을 잡을 수 있다.
- YES/NO: CPU 사용률은 낮은데 요청 지연(p95/p99)만 크게 늘어나는가?
- YES/NO: 특정 기능/특정 키/특정 계정처럼 "한 지점"에 트래픽이 몰리는가?
- YES/NO: 스레드 덤프나 프로파일러에서 BLOCKED/WAITING 상태가 눈에 띄게 많은가?
- YES/NO: 락을 잡은 채로 I/O(네트워크/DB/파일)를 수행하는 구간이 존재하는가?
- YES/NO: 임계 구역 안에서 로그/직렬화/큰 객체 생성처럼 무거운 작업이 함께 수행되는가?
YES가 2개 이상이면 "락 경합이 병목일 가능성"이 충분히 있다.
실전 점검 절차: 어디서 막히는지 눈으로 확인하기
락 경합을 해결하려면 "락을 얼마나 오래 잡고 있는지"와 "누가 얼마나 기다리는지"를 먼저 확인해야 한다.
아래 절차는 서버/런타임에 따라 도구가 달라도 흐름은 동일하다.
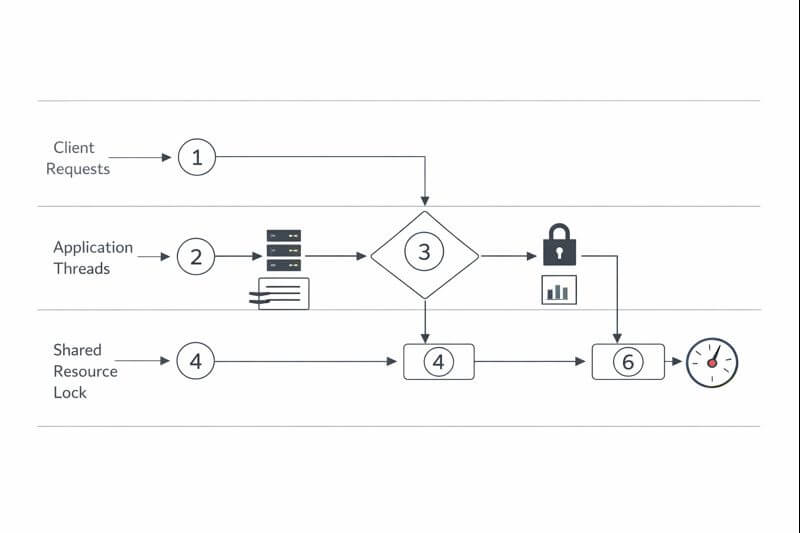
- 관측 시작: APM/모니터링에서 지연이 큰 엔드포인트(또는 작업)를 고른다.
- 대기 확인: 스레드 상태에서 BLOCKED/WAITING 비율과 급증 시점을 확인한다.
- 락 위치 확인: 스레드 덤프/프로파일러로 "어떤 락에서" 막히는지 찾는다.
- 임계 구역 길이 확인: 락을 잡은 채 수행되는 작업(쿼리/네트워크/직렬화)을 분리한다.
- 경쟁 분산: 락 범위를 줄이거나, 키 기준으로 분할하거나, 락 대신 다른 동기화 방식(큐/원자 연산 등)을 검토한다.
- 검증: 동일 트래픽에서 p95/p99와 BLOCKED 수치가 내려가는지 확인한다.
예를 들어 JVM 기반 서버라면 "스레드 덤프"로 락 경합을 빠르게 볼 수 있다.
예시 관측 로그(민감정보 제거) p95_latency=980ms, blocked_threads=47, cpu=32%이 값이 함께 움직이면 "CPU가 아니라 대기"가 병목일 가능성이 커진다.
확인 경로/메뉴 예시는 아래처럼 잡을 수 있다.
- VisualVM: 메뉴 경로 "Threads" 탭에서 BLOCKED 스레드와 스택 트레이스를 확인한다.
- IntelliJ Profiler: 메뉴 경로 "Run → Attach Profiler to Process"로 붙인 뒤, 동기화/대기 이벤트를 확인한다.
- Linux: 터미널에서 스레드 덤프를 수집한 뒤, 동일한 락 주소/모니터에서 반복 대기가 있는지 확인한다.
실전 예시는 "락을 잡은 채로 DB 호출을 하는 코드"가 있을 때 자주 벌어진다.
트래픽이 늘면 DB 응답이 조금만 느려져도 임계 구역이 길어지고, 그 순간 락 대기열이 폭발해 전체가 느려진다.
이 경우 선택지는 보통 세 가지다.
- 락 범위를 줄여서 DB 호출은 임계 구역 밖으로 빼고, 공유 데이터 갱신만 최소화한다.
- 공유 자원을 키 단위로 쪼개 락을 여러 개로 분산한다(한 락에 몰리지 않게 한다).
- 동기화를 "락"이 아니라 "큐 기반 단일 소비자" 같은 형태로 바꿔 경쟁 자체를 없앤다.
결론
락(Lock)은 데이터 안전을 지키지만, 락 경합이 생기면 대기열이 쌓이며 지연이 급격히 커진다.
느려지는 이유는 락 자체가 아니라 임계 구역이 길어지거나 경쟁 대상이 한 곳에 몰려 "줄 서기"가 폭발하기 때문이다.
해결의 방향은 락 범위를 줄이고, 경쟁 대상을 분산하며, 대기와 임계 구역 길이를 수치로 확인해 검증하는 것이다.
연계 주제로는 원자 연산(Atomic)과 락의 역할 분담, 큐 기반 처리로 경합을 구조적으로 제거하는 방법이 이어진다.
FAQ
Q1. 락(Lock)을 더 촘촘히 걸면 무조건 안전하고 빠른가
안전성은 좋아질 수 있지만 빠르다고 보장되지 않는다.
락 범위가 늘거나 락 획득 횟수가 늘면 락 경합이 더 쉽게 생긴다.
Q2. 락 경합은 CPU가 높을 때만 발생하는가
그렇지 않다.
CPU가 낮아도 BLOCKED/WAITING이 늘면 락 경합으로 지연이 커질 수 있다.
Q3. 락 경합을 줄이기 위한 가장 확실한 첫 조치는 무엇인가
임계 구역에서 I/O와 무거운 작업을 빼서 "락을 잡고 있는 시간"을 줄이는 것이다.
그다음에 경쟁 대상을 분산하거나 구조를 바꿔 재발을 막는 편이 안정적이다.
'전산학' 카테고리의 다른 글
| 이벤트 루프(Event Loop) 개념: 자바스크립트·서버가 많은 요청을 처리하는 방식 (0) | 2026.01.03 |
|---|---|
| 레이스 컨디션: “가끔만” 터지는 버그가 생기는 구조와 예방 방법 (0) | 2026.01.02 |
| CAP 정리 쉽게 이해하기: 일관성·가용성·분할 허용 중 무엇을 선택하는가 (0) | 2026.01.02 |
| 분산 시스템에서 ‘일관성’이란 무엇인가: 동시에 업데이트할 때 데이터가 어긋나는 이유 (0) | 2026.01.02 |
| 트래픽을 고르게 나누는 핵심: Consistent Hashing으로 캐시/샤딩 리밸런싱을 줄이는 원리 (0) | 2026.01.01 |



